Árvore de decisão é uma classe de algoritmos de Aprendizado supervisionado aplicado em problemas de classificação, ou seja, problemas nos quais a partir de um conjunto de atributos deseja-se obter um novo atributo discreto (uma classe).
A ideia é representar o processo de identificação da classe como uma árvore na qual cada os nós internos são atributos e os nós folhas são as possíveis classes.
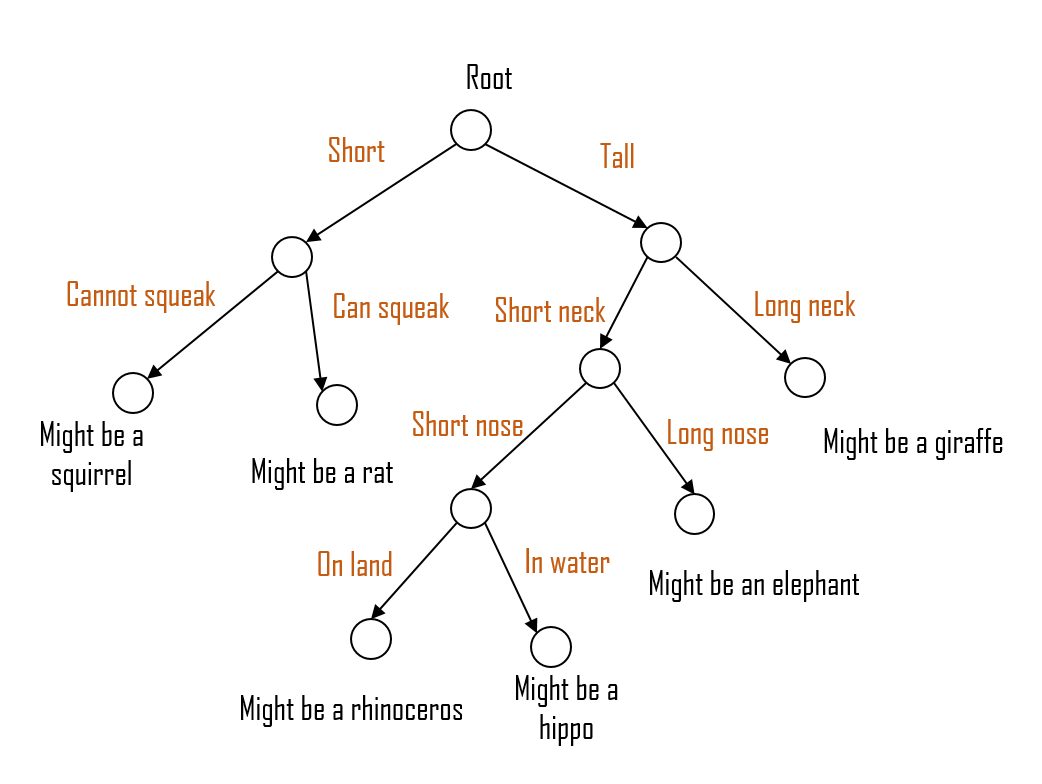
Para gerar uma árvore de decisão é necessário particionar o conjunto de treinamento com base em um atributo até que os conjuntos resultantes do particionamento contenham dados de uma única classe. Para avaliar qual atributo escolher para particionar o conjunto de treinamento em cada nó da árvore, é possível utilizar algumas medidas:
- Entropia: Medida de incerteza de uma variável randômica
- Ganho de informação: redução em entropia
Dessa forma, é dada prioridade ao atributo que oferece o maior ganho de informação para cada conjunto de dados. O algoritmo selecionar o atributo consiste em:
- Calcular a entropia do conjunto de dados
- Calcular o ganho de informação de cada atributo
- Selecionar o atributo com o maior ganho de informação
Dado um conjunto de dados com classes, o cálculo da entropia do conjunto é dado por:
no qual:
onde corresponde ao número de exemplos da classe e corresponde ao número total de exemplos no conjunto de dados.
O ganho de informação de um atributo é a redução da entropia com a escolha desse atributo. Para calcular o ganho de informação é necessário calcular a entropia de todos os subconjuntos gerados pela escolha de um atributo. Dessa forma, o ganho de informação resultante da escolha de um atributo em um conjunto de dados é dado por:
Onde corresponde a entropia restante. Dado que a escolha de um atributo que pode assumir valores distintos divide o conjunto em subconjuntos , a entropia restante é dada por: