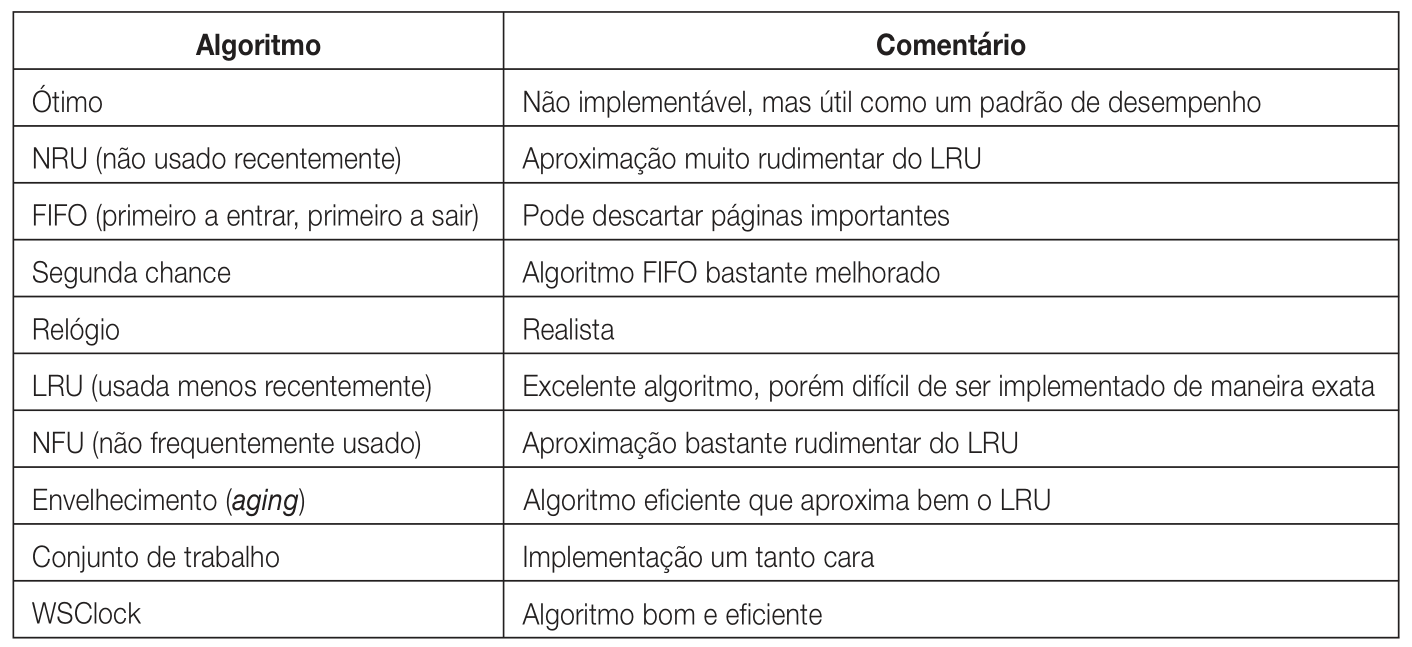
Substituição de páginas
Em um sistema de memória virtual utilizando paginação, quando ocorre uma falta de página, é necessário buscar a página armazenada em disco e, se necessário, escolher uma página para remover da memória principal. Se a página removida foi alterada na memória principal, é necessário então reescrever essas alterações em disco, caso contrário não há essa necessidade. Nota-se que há uma complexidade grande na substituição de páginas, principalmente porque é uma operação que depende muito de acesso ao disco (uma operação custosa), então é desejável que a substituição de páginas seja feita de uma forma cuidadosa e eficiente.
Para resolver esse problema, foram desenvolvidos diversos algoritmos de substituição de páginas, cada um com suas particularidades teóricas e de implementação.
Algoritmo ótimo de substituição de página
Esse algoritmo representa a melhor implementação possível para um algoritmo de substituição de páginas. Naturalmente, sua implementação é de fato impossível, porém ele ainda serve como um parâmetro de comparação e um modelo para os demais algoritmos de substituição de páginas.
Nesse algoritmo a ideia é rotular cada página com o número de instruções que serão executadas antes que a página seja referenciada novamente. Dessa forma, quando há uma falta de página, a página carregada na memória com o maior valor de rótulo é aquela que deve ser substituída, dessa forma é possível adiar ao máximo a próxima falta de página.
Com isso já é possível perceber porque o algoritmo não pode ser implementado. Primeiro porque não é possível determinar de antemão quantas instruções serão executadas antes que uma página seja referenciada, pois isso depende de diversos fatores tanto de escalonamento do sistema quanto de fatores externos. Outro ponto que impossibilita a implementação desse algoritmo é a atualização dos rótulos de cada página. Se a cada instrução fosse necessário decrementar o rótulo de todas as páginas, isso representaria um custo altíssimo de processamento.
Apesar dessas questões, esse algoritmo é muito utilizado de maneira teórica para determinar quão bom é um algoritmo que pode de fato ser implementado. Quanto menor a diferença de desempenho entre um algoritmo possível de ser implementado e o algoritmo ótimo, melhor é esse algoritmo (pelo menos na questão de desempenho).
Substituição de páginas não usadas recentemente (NRU)
Esse algoritmo faz uso dos bits M e R presentes em cada entrada na tabela de páginas, onde o bit M indica que a página foi alterada na memória, e o bit R indica que a página foi referenciada. Esses bits podem ser alterados pelo sistema operacional de acordo com políticas específicas. Por exemplo, é conveniente que o bit R seja limpo (setado para 0) periodicamente, afim de distinguir páginas recentemente referenciadas daquelas que não foram referenciadas recentemente.
Com esse algoritmo, quando ocorre uma falta de página, o sistema operacional inspeciona as páginas e as divide em quatro categorias baseadas nos valores atuais dos bits R e M:
- Classe 0: não referenciada, não modificada
- Classe 1: não referenciada, modificada
- Classe 2: referenciada, não modificada
- Classe 3: referenciada, modificada
O algoritmo remove uma página ao acaso da classe de ordem mais baixa. Isto é, o algoritmo dá preferência para remover as páginas de classe mais baixa antes das de classe mais alta. Essa implementação é simples e não exige novos recursos de hardware ou complexidade adicional de software, e em geral apresenta um desempenho mediano e aceitável para a maioria das situações.
Primeiro a entrar, primeiro a sair (FIFO)
Esse algoritmo se baseia na ideia primordial de inserção e remoção de filas. O sistema operacional mantém uma lista encadeada de todas as páginas atualmente na memória. Quando ocorre uma falta de página, a primeira página da lista é removida e a nova página é adicionada no final da lista. Apesar de ser simples e intuitivo, esse algoritmo é raramente utilizado, pois a página mais antiga da memória ainda pode estar sendo usada, portanto não é necessariamente uma boa candidata para substituição.
Segunda chance
Uma melhoria simples no algoritmo FIFO resulta em um algoritmo mais eficiente e que de fato pode ser utilizado. O funcionamento do algoritmo segunda chance é similar ao FIFO, com a diferença de que o bit R da página mais antiga é inspecionado antes de removê-la da memória. Se o bit for 0, a página é pouco utilizada, portanto pode ser substituída imediatamente, caso contrário, a página é colocada no final da lista, seu bit R é limpo, e a próxima página é verificada.
Essa implementação garante que páginas recentemente referenciadas não serão removidas da memória, como acontece no algoritmo FIFO. Note, entretanto, que se todas as páginas possuírem o bit R com o valor 1, o algoritmo percorre toda a lista de páginas e então remove a mesma página que seria removida por um algoritmo FIFO simples.
Algoritmo do relógio
Esse algoritmo é muito similar ao algoritmo da segunda chance, porém é implementado com uma lista circular. A implementação com uma lista circular elimina a necessidade de mover as páginas para o final da lista, como ocorre no algoritmo da segunda chance. O nome do algoritmo deriva do fato de que as páginas estão armazenadas em uma lista circular, com um ponteiro apontando para a página mais antiga.
Quando ocorre uma falta de página, a página apontada pelo ponteiro é verificada. Se o bit R da página for 0, a página é removida, a nova página é inserida em seu lugar e o ponteiro avança uma posição na lista. Caso contrário, o bit é setado para 0 e o ponteiro avança para a próxima página.
Substituição de páginas usadas menos recentemente (LRU)
Pelo princípio da localidade, páginas que foram recentemente referenciadas tem mais chances de serem referenciadas em seguida. É nesse princípio, ou melhor, no seu inverso, que se baseia o algoritmo LRU. Nesse algoritmo, quando ocorre uma falta de página, a página a ser substituída é aquela que não foi usada há mais tempo, pois é a página que tem menos chance de ser referenciada em seguida.
A ideia do algoritmo é razoável e de fato é uma ótima estratégia, porém com ela se introduz um problema: como verificar qual página é a que não tem sido referenciada há mais tempo? Essa é a principal questão que torna esse algoritmo caro e complexo. Uma implementação possível é manter uma lista encadeada de todas as páginas carregadas na memória principal, com a página mais recentemente utilizada no começo da lista e a menos recentemente utilizada no final. O problema dessa implementação é que, a cada referência de memória, é necessário atualizar a lista encadeada para colocar a página referenciada no começo.
Existem ainda outras implementações do algoritmo LRU envolvendo hardware dedicado. A maneira mais simples é adicionar um contador de 64 bits que é automaticamente incrementado a cada instrução. Com essa implementação, é necessário que cada entrada da tabela de páginas tenha um campo grande o bastante para armazenar o valor do contador. Após cada referência de memória, o valor atual do contador é armazenado na entrada da tabela de páginas referenciada. Quando ocorre uma falta de página, o sistema operacional substitui a página com o valor de contator mais baixo, pois essa é a página menos recentemente utilizada.
Working set
O algoritmo working set se baseia na ideia de um conjunto de páginas que provavelmente serão utilizadas pelo processo em um determinado intervalo de tempo. Ao invés de carregar as páginas na memória apenas quando ocorre uma falta de página, a ideia do algoritmo working set é evitar ao máximo as faltas de página carregando um conjunto de páginas recentemente referenciadas e só executar o processo quando todo o conjunto estiver carregado na memória principal. O conjunto de trabalho de um processo é o conjunto de páginas que ele referenciou durante os últimos segundos de tempo virtual (tempo de CPU do processo).
Quando ocorre uma falta de página, a ideia é encontrar uma página que não esteja no conjunto de trabalho atual, isto é, uma página que não tenha sido referenciada recentemente, e substituí-la pela nova página.
WSClock
Esse algoritmo é a junção do algoritmo de relógio e o algoritmo baseado em working set. Combinando simplicidade e um bom desempenho, esse algoritmo é um dos mais utilizados na prática. Todas as páginas carregadas na memória são armazenadas em uma lista encadeada circular, com um ponteiro apontando para a primeira página. A diferença é que em cada item da lista é armazenado também o tempo do último acesso à página.
Quando ocorre uma falta de página, a página apontada é verificada, se o bit R for 1, a página foi usada recentemente, portanto não deve ser removida, então o bit R é setado para 0 e o ponteiro avança para a próxima página. Caso contrário, verifica-se o campo de tempo da página, se o tempo for maior do que o tempo atual e a página está limpa, isto é, se ela não foi alterada na memória, então ela não está no conjunto de trabalho e pode ser facilmente removida sem precisar ser reescrita em disco. Caso a página esteja suja, ou seja, caso não haja uma cópia válida presente no disco, a escrita da página no disco é escalonada, porém o ponteiro avança para a posição seguinte afim de encontrar alguma página que possa ser substituída imediatamente.
É comum que se estabeleça um limite de páginas que podem ser escalonadas para escrita em disco, isso garante que, caso muitas páginas estejam sujas, nem todas serão escalonadas para escrita. Se o ponteiro der uma volta completa na lista, o algoritmo verifica se alguma página foi escalonada para escrita, se for o caso então a busca prossegue, pois eventualmente a página será escrita em disco e poderá ser substituída. Caso nenhuma página tenha sido escalonada para escrita em disco, então todas as páginas estão no conjunto de trabalho, portanto o melhor a se fazer é escolher a próxima página limpa para ser substituída.