Estou aprendendo Go pelo livro Learning Go.
Go é uma linguagem compilada e estaticamente tipada desenvolvida com o propósito de ser simples, eficiente, e fazer uso dos recursos computacionais de computadores modernos. Pode-se pensar nela como um potencial substituto para a linguagem C em algumas aplicações.
If you had to label Go’s style, the best word to use is practical. It borrows concepts
from many places with the overriding goal of creating a language that is simple, read‐
able, and maintainable by large teams for many years.A linguagem é feita com praticidade em mente. Um exemplo disso é o estilo único de formatação de código. Isso não só extingue quaisquer discussões sobre formatação como também simplifica o desenvolvimento do compilador da linguagem e também de ferramentas que analisam o código.
O possui uma regra para a inserção de ”;” diretamente no compilador, o que o torna mais simples rápido.
Tipos primitivos
Go tem vários tipos de dados, e bastante variações de alguns tipos que permitem setar explicitamente o tamanho. Apesar disso parece que, a não ser que seja uma situação bastante específica, o uso de tipos com tamanho explícito não é idiomático na linguagem.
Unless you need to be explicit about the size or sign of an integer for performance or integration purposes, use the int type. Consider any other type to be a premature optimization until proven otherwise.
Go possui suporte nativo para tipos complexos. Parece que é uma feature interessante pra implementar uns processamentos de imagem e cálculos do tipo. Apesar disso, Go não é uma linguagem muito recomendada para esse tipo de cálculo.
Não há conversão implícita de tipos em Go. Todas as conversões de tipos devem ser feitas explicitamente, até mesmo em operações envolvendo tipos que apenas diferem em tamanho. Uma implicação disso é que não há o conceito de truthy ou falsy, pois não há conversão implícita para booleanos. Sendo assim, apenas os valores true e false possuem semântica de valor-verdade. Isso é bastante interessante, pois parece trazer bastante clareza no código, apesar de introduzir mais verbosidade.
Em Go declarar uma variável e nunca utilizá-la (leitura) gera um erro de compilação. Uma feature bastante única e interessante, apesar de não me parecer muito útil ela contribui para a qualidade do código.
Se tratando de convenção de nomes, Go parece seguir uma abordagem mais pragmática, favorecendo o uso de nomes curtos caso o escopo da variável seja pequeno.
Within a function, favor short variable names. The smaller the scope for a variable, the shorter the name that’s used for it. It is very common in Go to see single-letter variable names. For example, the names k and v (short for key and value) are used as the variable names in a for-range loop. If you are using a standard for loop, i and j are common names for the index variable. There are other idiomatic ways to name variables of common types; we will mention them as we cover more parts of the standard library.
Tipos compostos
Em Go a principal estrutura de enumeração são os Slices, que são arrays de tamanho variável. Go também tem arrays, mas em geral eles não são muito usados, pois só é possível definir seu tamanho em tempo de compilação.
É possível adicionar itens aos slices usando a função append, para concatenar dois slices podemos utilizar o append em conjunto com o operador ....
x := []int{10}
y := []int{20, 30, 40}
x = append(x, y...)Assim como nos arrays, os elementos dos slices são armazenados de maneira contígua na memória. Todo slice tem uma capacidade, que é o número de elementos alocados (não necessariamente utilizados no momento). Quando adicionamos mais elementos do que a capacidade do slice, o runtime do Go aloca um novo slice com maior capacidade e copia os valores do slice original para o novo endereço alocado, juntamente com os novos elementos. Dessa forma conseguimos a flexibilidade de uso de listas aliada à velocidade dos arrays. Vale notar que alocação de memória é uma operação cara, pois envolve uma syscall, portanto quando o número de elementos de um slice excede a capacidade o runtime não aloca um novo slice com apenas um elemento a mais, e sim um slice com capacidade bem maior (dobrando o tamanho quando a capacidade é menor que 1024 e depois disso crescendo em 25%).
É importante notar que, se sabemos a priori quantos elementos esperamos ter no slice, devemos inicializá-lo com esse tamanho para evitar alocações extras. Isso pode ser feito com a função make:
x := make([]int, 10)Go implementa maps como hash tables. Em geral eles funcionam de maneira bastante parecida com os slices. Qualquer tipo comparável pode ser a chave de um map, o que significa que não podemos usar slices ou maps como chaves de um map, já que eles não são tipos comparáveis.
Podemos remover elementos de um map com a função delete:
m := map[string]int{
"hello": 5,
"world": 10,
}
delete(m, "hello")Structs são formas de estruturar dados em tipos compostos.
type person struct {
name string
age int
pet string
}Estruturas de controle
Em Go cada bloco de escopo é definido por um conjunto de chaves {}. É possível fazer shadowing de variáveis redeclarando elas em um novo bloco, e é necessário ficar atento com o comportamento de shadowing quando usando assignment com := para múltiplas variáveis.
No exemplo a seguir, o assignment múltiplo de x e y faz shadowing da variável x no escopo do bloco if.
func main() {
x := 10
if x > 5 {
x, y := 5, 20
fmt.Println(x, y)
}
fmt.Println(x)
}É possível declarar variáveis no escopo tanto do if quanto de todos os blocos else utilizando ; na definição da condição do if:
if n := rand.Intn(10); n == 0 {
fmt.Println("That's too low")
} else if n > 5 {
fmt.Println("That's too big:", n)
} else {
fmt.Println("That's a good number:", n)
}Em Go a única estrutura de repetição é o for, e existem quatro formatos para ela:
- Um
forcompleto, no estilo de C; - Um
forassociado uma condição, parecido com um while; - Um
forinfinito, sem especificar nenhuma condição; - Uma iteração por tipos compostos com o
for-range, sendo possível iterar sobre strings, arrays, slices, maps e channels.
Switch cases em Go tem alguns upgrades em relação aos de C. Não é necessário adicionar um break no final de cada caso, e é possível especificar múltiplas condições para um mesmo caso. Também é possível não especificar nenhum valor para a condição do switch, permitindo especificar qualquer expressão booleana para definir cada caso.
Surpreendentemente, Go tem o goto, e é bem raro precisar utilizá-lo.
As estruturas de controle da linguagem tem uma cara bastante procedural/imperativa tradicional (o que não surpreende, devido à similaridade com a linguagem C).
Funções
Go possui um comportamento bastante normal pra funções. Funções são first-class citizens em Go, o que traz bastante praticidade. Achei os named return parameters um tanto confusos, eles criam variáveis implicitamente e acabam criando um comportamento bastante perigoso quando aliados aos blank returns. Funções anônimas são closures, e com o suporte a higher-order functions é possível fazer bastante coisa interessante com elas.
É possível especificar chamadas de função a serem executadas ao final da execução da função atual usando o defer. Isso é especialmente útil para garantir a limpeza de recursos (como file handles e sockets) independentemente de quantos caminhos de retorno a função tenha. Também é possível manipular as variáveis de retorno criadas com named returns e, pois as funções especificadas com defer rodam após o return.
file, err := os.Open("filename")
if err != nil {
log.Fatal(err)
}
defer file.Close()Em Go os parâmetros são sempre passados por valor. Entretanto, maps e slices são passados por referência. Sendo assim, é possível gerar efeitos colaterais nos maps e slices recebidos como parâmetros, porém não é possível alterar o tamanho dos slices (adicionando elementos, por exemplo). Achei o comportamento de não poder alterar o tamanho do slice bastante estranho, mas parece adicionar uma segurança extra para o comportamento.
Every type in Go is a value type. It’s just that sometimes the value is a pointer.
Ponteiros
Ponteiros em Go funcionam de maneira bastante similar ao de C. Os operadores & e * funcionam como o esperado. Apesar disso, não é possível fazer aritmética de ponteiros. Minha primeira impressão é de que a ideia dos ponteiros em Go é fornecer ferramentas básicas de gerenciamento de memória mesmo que a linguagem tenha GC, atingindo um trade-off bastante interessante.
Most of the time, you should use a value. They make it easier to understand how and when your data is modified. A secondary benefit is that using values reduces the amount of work that the garbage collector has to do.Em Go o principal caso de uso para ponteiros é indicar se um parâmetro pode ou não ser modificado pela função que o recebe.
Usar ponteiros para retornar e receber valores em funções só representa um ganho de performance quando as estruturas de dados passam de 10 megabytes. Caso contrário, na verdade é mais rápido (e legível) retornar e receber valores ao invés de referências para as estruturas.
Quando passamos um slice ou map para uma função, copiamos suas referências. Entretanto, como um slice é composto por um ponteiro para o array e dois campos de tamanho e capacidade que não são ponteiros, quando recebemos um slice como parâmetro conseguimos apenas alterar seus elementos, e não seu tamanho ou capacidade.
#+caption: Layout de memória de um slice passado como parâmetro#+attr_org: :width 500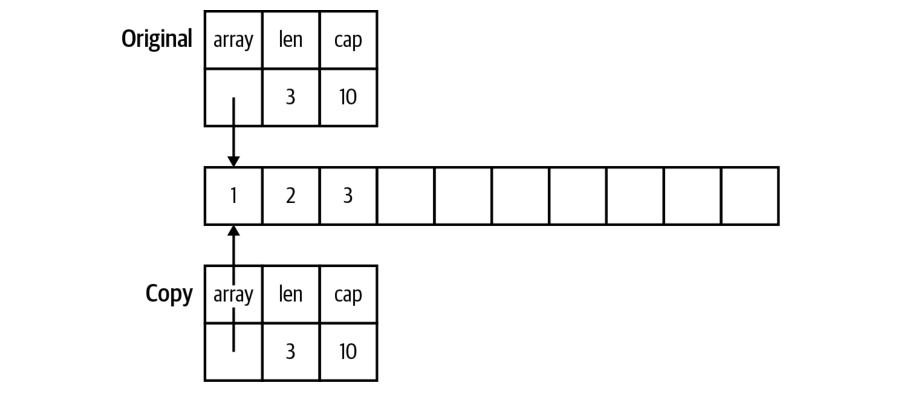
Por padrão devemos assumir que funções não irão modificar slices passados como parâmetro a não ser que sua documentação deixe isso explícito.
Alocação de memória e o Garbage Collector
Variáveis alocadas na stack têm seu life-cycle limitado à execução da função na qual foram declaradas, já as variáveis alocadas em heap têm seu life-cycle limitado à execução do programa. Alocar na stack é mais rápido do que no heap.
Em C, quando retornamos um ponteiro para uma variável local da função isso resulta em um ponteiro que aponta para uma área inválida de memória, já que a variável foi alocada na stack. Já em Go, quando retornamos um ponteiro para uma variável local o compilador entende que tal variável deve ser alocada no heap, e não na stack.
O GC gerencia a memória alocada em heap do programa. Portanto, vale destacar que quando alocamos variáveis no heap aumentamos a carga de trabalho do GC, pois agora há mais memória para ser gerenciada.
Dessa forma, em Go a forma mais idiomática de escrever código também é a mais eficiente: usar ponteiros apenas quando estritamente necessário para atingir mutabilidade, recebendo e retornando valores quando possível para que eles sejam alocados na stack da função e não gerem mais carga para o GC.
É bastante interessante que a forma mais simples também é a mais performática em Go. A linguagem faz com que seja óbvio e intuitivo escrever código de forma a extrair o melhor do GC. Dessa forma não é necessário se preocupar com otimizações envolvendo ponteiros em recebimento ou retorno de funções.
Esse vídeo explica muito bem a dinâmica de uso de ponteiros e alocação em stack vs heap.
Métodos
Em Go, métodos são funções declaradas sobre tipos. A diferença deles para funções comuns são que eles possuem um receiver, um valor de um dado tipo. Vale destacar que métodos só podem ser declarados no mesmo pacote no qual o tipo foi declarado. Sendo assim, não é possível adicionar métodos para tipos de módulos externos.
type Person struct {
FirstName string
LastName string
}
func (p Person) Greet(args) string {
return fmt.Sprintf("Hello %s %s!", p.FirstName, p.LastName)
}O receiver de um método pode ser passado via valor ou ponteiro. Em geral, se deseja-se alterar o valor do receiver deve-se utilizar ponteiros. É comum que todos os métodos de um mesmo tipo adotem um padrão com relação a isso.
Whether or not you use a value receiver for a method that doesn't modify the receiver depends on the other methods declared on the type. When a type has any pointer receiver methods, a common practice is to be consistent and use pointer receivers for all methods, even the ones that don’t modify the receiver.Também vale notar que métodos com value receivers não conseguem lidar com a invocação de métodos em valores nil, pois o runtime irá desreferenciar o ponteiro para invocar o método, gerando um erro em runtime. Já quando utilizamos pointer receivers conseguimos lidar com isso verificando se o valor recebido não é nil.
Composição de tipos
Go favorece composição de tipos ao invés de herança entre classes. A principal característica da linguagem que facilita o uso de composição entre tipos é a promoção de métodos e propriedades entre tipos. Dessa forma, é possível compor diferentes tipos compostos e, através da promoção, utilizar os métodos e propriedades dos subtipos diretamente no tipo composto.
type Employee struct {
Name string
ID string
}
func (e Employee) Description() string {
return fmt.Sprintf("%s (%s)", e.Name, e.ID)
}
type Manager struct {
Employee
Reports []Employee
}
func main() {
m := Manager{
Employee: Employee{
Name: "Bob",
ID: "12345",
},
Reports: []Employee{},
}
fmt.Println(m.ID) // prints 12345
fmt.Println(m.Description()) // prints Bob (12345)
}Interfaces
Interfaces são o único tipo abstrato em Go. Elas definem um conjunto de métodos que um tipo concreto deve conter para implementar a interface. A parte mais interessante é que não há a declaração explícita de implementação de interfaces. Sendo assim, um tipo concreto implementa uma interface apenas definindo os métodos que a interface especifica, sem necessariamente declarar que está implementando tal interface. Dessa forma, é possível aliar a verificação estática com uma flexibilidade parecida com a de linguagens com duck typing.
Interfaces Are Type-Safe Duck TypingInterfaces vazias são implementadas por qualquer tipo. Sendo assim, elas geralmente são usadas para descrever valores que podem assumir qualquer tipo (como um any).
O fato de interfaces em Go serem implementadas de forma implícita por tipos concretos garante um maior desacoplamento entre clientes e provedores, tornando técnicas como injeção de dependência bastante simples de serem implementadas.
Type assertions
É possível fazer asserção de tipos em runtime para verificar qual o tipo concreto de um valor. Quando uma asserção falha ela causa um panic em runtime. Para evitar isso, podemos atribuir o resultado da asserção a duas variavéis, sendo que a segunda indica se a asserção foi bem sucedida ou não.
i2, ok := i.(int)
if !ok {
return fmt.Errorf("unexpected type for %v",i)
}
fmt.Println(i2 + 1)É possível ainda fazer asserções de tipos em combinação com um switch, definindo diferentes caminhos de execução com base no tipo concreto de uma variável.
func doThings(i interface{}) {
switch j := i.(type) {
case nil:
// i is nil, type of j is interface{}
case int:
// j is of type int
case MyInt:
// j is of type MyInt
case io.Reader:
// j is of type io.Reader
case string:
// j is a string
case bool, rune:
// i is either a bool or rune, so j is of type interface{}
default:
// no idea what i is, so j is of type interface{}
}
}Apesar de serem possíveis, as asserções de tipos raramente são usadas em cenários reais, e geralmente são mais úteis ao desenvolver bibliotecas que devem ter uma certa flexibilidade na API.
Erros
Ao invés de usar exceções, Go trata erros como valores. A convenção é que uma função que pode falhar deve sempre retornar um valor do tipo error como último parâmetro de retorno.
Error messages should not be capitalized nor should they end with punctuation or a newline.Erros em runtime geralmente são representados por panics. Quando ocorre um panic, a execução da função é imediatamente interrompida e todas as funções defer da stack são executadas em ordem, viabilizando o teardown dos recursos, e então o programa termina com uma mensagem de erro e uma stack trace.
A função recover pode ser executada dentro de uma função defer para capturar um panic e continuar a execução do programa. Geralmente o recover deve ser usado apenas para executar alguma tarefa antes da finalização do programa, como escrever logs ou adicionar algum dado em um sistema de monitoramento.