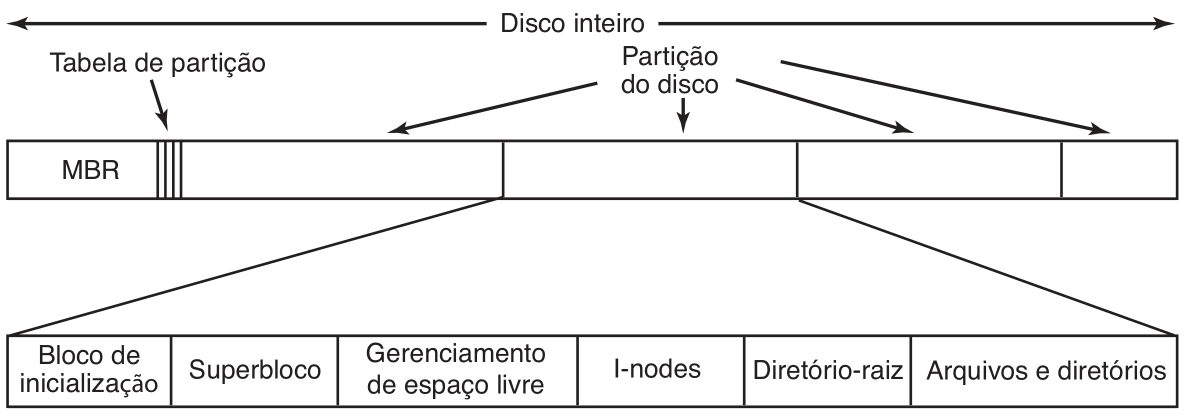
Os discos de armazenamento são divididos em diferentes setores, e podem ser particionados de diversas formas. O setor 0 do disco é chamado de MBR, e é utilizado para inicializar o computador. No final do MBR está a tabela de partição, que fornece os endereços de início e fim de cada partição do sistema. Na tabela, uma das partições do disco é sempre marcada como ativa. A função do MBR é, através da tabela de partição, encontrar a partição ativa e ler seu primeiro bloco, chamado de bloco de inicialização. O bloco de inicialização é responsável por carregar o sistema operacional contido naquela partição. Há também muitas vezes um superbloco na partição, que armazena parâmetros sobre o sistema de arquivos daquela partição.
Implementação de arquivos
A implementação de arquivos se baseia em um método de mapear cada bloco de disco a um arquivo do sistema. Tendo isso em vista, existem diversas maneiras de implementar arquivos em um disco. Aqui serão abordadas apenas algumas das alternativas usadas para a implementação de arquivos em um sistema de arquivos.
Alocação contígua
Esse é o esquema de alocação mais simples, a ideia é apenas alocar cada arquivo sequencialmente nos blocos do disco de acordo com seu tamanho. Dessa forma, em um disco com blocos de 1 KB, um arquivo de 10 KB seria alocado em 10 blocos consecutivos.
Esse método é muito simples de ser implementado, basta saber o endereço do primeiro bloco e a quantidade de blocos ocupados por cada arquivo. Uma consequência dessa simplicidade é a velocidade de leitura, pois é possível acessar qualquer bloco do disco através de simples adições, e quando o arquivo é encontrado no disco, ele pode ser lido diretamente sem nenhuma instrução adicional, pois está armazenado naquele único agrupamento sequencial de blocos.
A principal desvantagem da alocação contígua é a fragmentação excessiva do disco, pois quando os arquivos são excluídos e os blocos liberados, não é simples preencher essas lacunas no disco. A fragmentação pode ser resolvida através da compactação do disco, mas essa é uma operação muito custosa e demorada, portanto não é de fato uma solução para o problema dado o quão frequentemente seria necessário compactar o disco.
Alocação por lista encadeada
Esse método se baseia em manter uma lista encadeada de blocos do disco. A primeira palavra de cada bloco armazena o endereço do próximo bloco do arquivo. Apesar de reduzir muito a fragmentação de disco, esse método torna as operações de leitura extremamente lentas. Isso se dá pela natureza de acesso das listas encadeadas. Para ler qualquer bloco do disco, é necessário visitar todos os blocos que estão antes dele na lista, e isso torna as operações de leitura de disco extremamente lentas e inviáveis.
Alocação por lista encadeada usando uma tabela na memória
Essa implementação se baseia exatamente no mesmo conceito da alocação por lista encadeada, mas ao invés de manter a lista em disco através da primeira palavra de cada bloco, agora essas informações referentes ao próximo bloco de cada bloco de arquivo ficam armazenadas em uma tabela na memória principal. Dessa forma, apesar do acesso ainda ser sequencial, agora ele é feito na memória principal, o que o torna muito mais rápido do que em disco. Além disso, não é mais necessário armazenar informações sobre o próximo bloco do arquivo nos blocos do disco, então eles podem agora armazenar apenas os dados relevantes de fato para o arquivo. Essa tabela é chamada de FAT (File allocation Table) e foi intensamente usada no MS-DOS, sendo suportada pela maioria das Windows.
A principal desvantagem desse método é a necessidade de manter toda a tabela na memória. Com o tamanho dos discos atuais e a quantidade de blocos que precisam ser mapeados, o tamanho dessa tabela se torna rapidamente grande demais para ser mantido na memória principal.
I-nodes
A implementação através de I-nodes é uma sofisticação da ideia de manter uma tabela de blocos na memória. Nesse método, a cada arquivo é associado uma estrutura de dados chamada de i-node (index-node). Essa estrutura armazena os atributos e os endereços dos blocos que compõe o arquivo em disco.
A vantagem desse método sobre a tabela de blocos é que o i-node só precisa ser mantido na memória enquanto o arquivo estiver aberto, após isso ele pode ser armazenado em disco novamente. Dessa forma, ao invés de manter uma estrutura mapeando todo o disco na memória, é possível manter pequenas estruturas que mapeiam apenas um arquivo.
Implementação de diretórios
O ponto da implementação de diretórios é permitir que os arquivos possam ser localizados no disco para então serem abertos, independente da forma como os arquivos em si são armazenados no disco. A ideia é implementar um mecanismo que permita que o sistema operacional, com base em um caminho de arquivo fornecido pelo usuário, seja capaz de localizar a entrada de diretório - que armazena as informações necessárias para encontrar os blocos dos arquivos - no disco.
De maneira geral, um diretório consiste em uma lista de entradas, cada entrada contém as informações de um arquivo. Essas informações podem incluir o nome do arquivo, uma estrutura de atributos e seus endereços em disco, ou também o i-node daquele arquivo, no caso de sistemas que utilizam esse tipo de implementação.
A principal dificuldade de implementação de diretórios é lidar com os tamanhos dos nomes dos arquivos. Atualmente os nomes dos arquivos possuem tamanhos grandes e variáveis, o que torna a implementação de um mapeamento de diretórios utilizando campos de tamanho fixo para os nomes dos arquivos bastante ineficientes em questão de espaço.
Para lidar com os nomes de arquivos variáveis, utilizam-se entradas de diretório compostas de duas partes:
- Uma parte de tamanho fixo, contendo o tamanho da entrada e uma cabeçalho com os atributos de arquivo relevantes para o sistema operacional.
- Uma parte de tamanho variável, contendo o nome do arquivo.
Essa separação de componentes da entrada de arquivos se mostra eficiente para lidar com os tamanhos variáveis dos arquivos, porém a forma como essas entradas são dispostas na lista do diretório ainda pode ser implementada de diversas formas. Organizar essas entradas de uma maneira sequencial introduz os mesmos problemas da alocação de arquivos contígua. Uma maneira mais eficiente de lidar com essa disposição é manter apenas a parte fixa das entradas de diretório na lista, e então armazenar a parte variável em um heap.
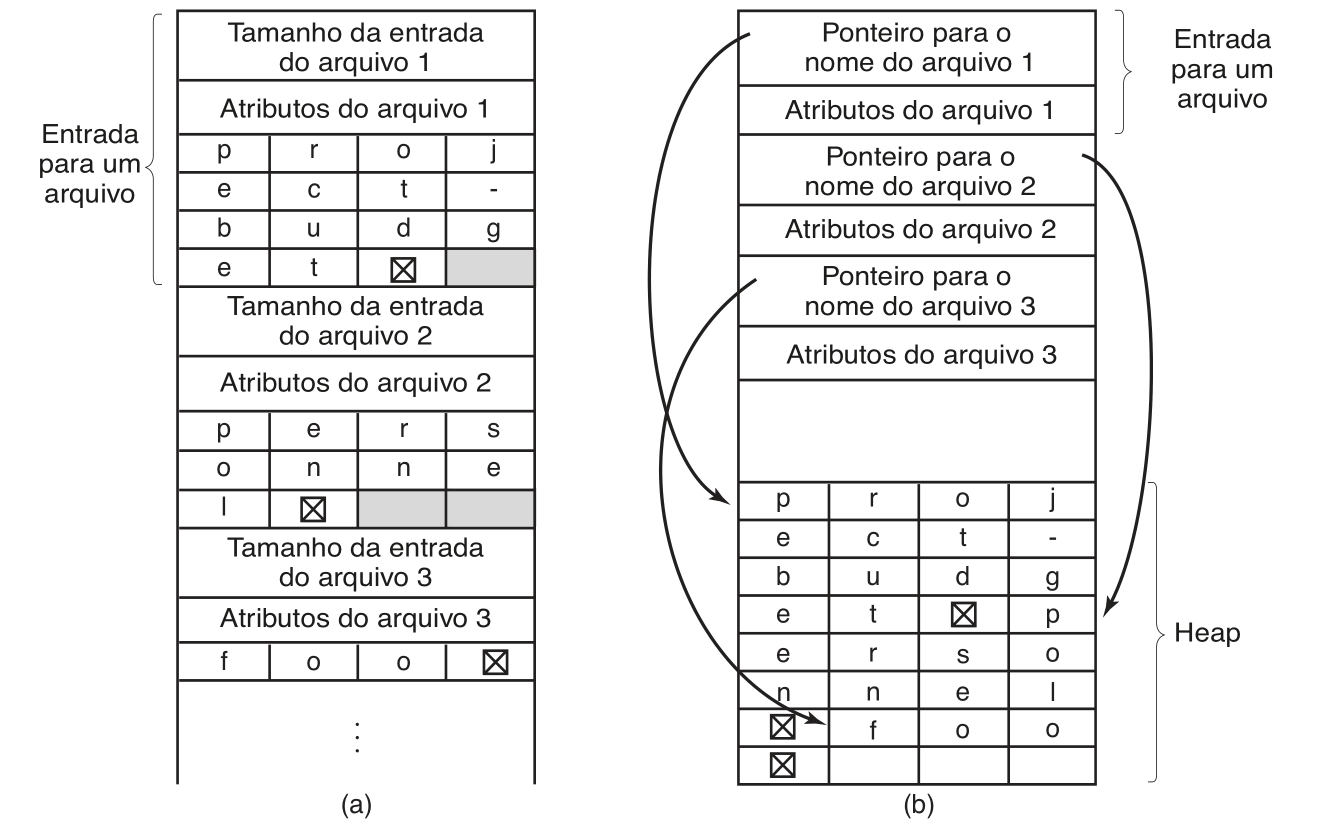
Há também a possibilidade de utilizar hash tables para acelerar a busca nessas tabelas. Nesse tipo de implementação o nome de cada arquivo é mapeado para um índice na tabela, dessa forma é possível buscar novamente o arquivo através de um acesso direto ao índice relacionado ao nome. O problema da implementação de hash tables é que ela é significativamente mais complexa, por isso sua implementação é utilizada apenas em sistemas nos quais é comum ter uma quantidade gigantesca de arquivos por diretório.
Arquivos compartilhados
O compartilhamento de arquivos entre usuários introduz problemas claros de acesso e permissões, mas também introduz problemas de implementação, pois agora é necessário que um mesmo arquivo seja apontado por diferentes lugares no sistema de arquivos (nesse caso diferentes diretórios de usuário). De maneira geral, existem duas formas de lidar com o compartilhamento de arquivos a nível de implementação.
A primeira maneira é fazer com que os blocos do disco sejam listados diretamente no i-node, dessa forma é possível que diversos usuários acessem o mesmo arquivo através do mesmo i-node. O i-node por sua vez passa a armazenar também o número de ligações, isto é, o número de vezes que ele é referenciado em tabelas de diretório. Essa maneira de compartilhar arquivos introduz sérios problemas, como a dificuldade de exclusão do arquivo. O arquivo só pode ser excluído quando todas as referências ao i-node forem excluídas. Isso pode gerar situações nas quais o proprietário do arquivo o exclui, mas o arquivo não é removido de fato, pois algum outro usuário possui o arquivo referenciado em sua pasta e ainda pode acessá-lo.
A segunda maneira é através de ligações simbólicas entre arquivos. Nesse tipo de implementação os usuários que acessam o arquivo compartilhado (todos exceto o proprietário do arquivo) possuem apenas o nome do caminho para o arquivo real. Dessa forma, quando o proprietário remove o arquivo, todas as referências feitas através de ligações simbólicas passam a referenciar um arquivo que não existe mais no sistema. Essa implementação também apresenta suas desvantagens, sendo a principal delas o overhead necessário para acessar os arquivos através de uma ligação simbólica. Ao invés de acessar o arquivo diretamente, é necessário acessar um arquivo contendo o endereço para o arquivo real, isso exige mais acesso ao disco do que normalmente seria necessário com o arquivo real.