Apesar da implementação pipeline proporcionar um aumento significativo de desempenho ela também introduz possíveis conflitos (hazards) na execução das instruções. Os hazards podem reduzir significativamente o ganho de desempenho alcançado pela implementação pipeline, porém existem soluções eficientes que visam minimizar a perda de desempenho.
Existem 3 tipos de hazards:
- Hazards estruturais: conflitos de unidades funcionais.
- Hazards de controle: ocorrem em desvios condicionais e incondicionais.
- Hazards de dados: ocorrem quando a execução de uma instrução depende do resultado de outra.
A solução mais imediata para resolver hazard é a utilização de paradas na execução das instruções (stalls), elas resolvem grande parte dos conflitos, porém causam perda de desempenho. Quando ocorre uma stall a execução de todas as instruções é parada e nenhuma nova instrução é buscada.
Hazards estruturais
Os hazards estruturais são conflitos causados pelo uso simultâneo de um mesmo recurso de hardware (unidade funcional). Esse tipo de conflito é mais frequente em arquiteturas onde não há distinção entre as memórias de instrução e dados, pois nesse caso toda instrução que faz acesso á memória (Load/Store) irá entrar em conflito com o estágio de busca de outras instruções.
No caso das implementações com uma única memória para dados e instruções é necessário o uso de diversas stalls para evitar os hazards, o que resulta em uma perda significativa de desempenho. Nesse caso a solução mais eficiente é utilizar memórias separadas para dados e instruções, evitando assim grande parte desses hazards sem perda alguma de desempenho.
A arquitetura MIPS, por exemplo, foi desenvolvida tendo em vista a implementação pipeline, por essa razão há a separação entre memória de dados e instruções.
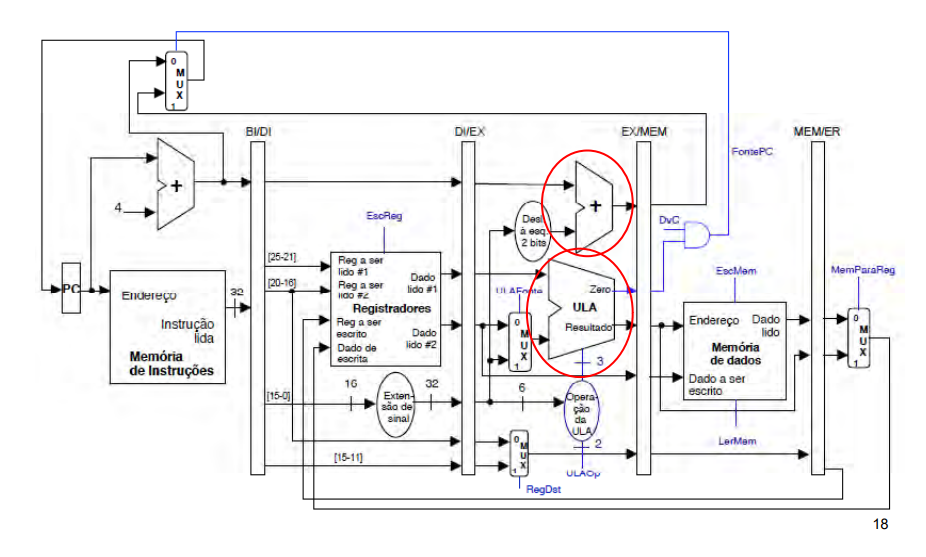
Outro conflito pode ocorrer com o uso da ULA quando estão sendo executadas instruções de salto. Para evitar esse conflito sem o uso de stalls implementa-se uma unidade de soma dedicada ao incremento do PC.
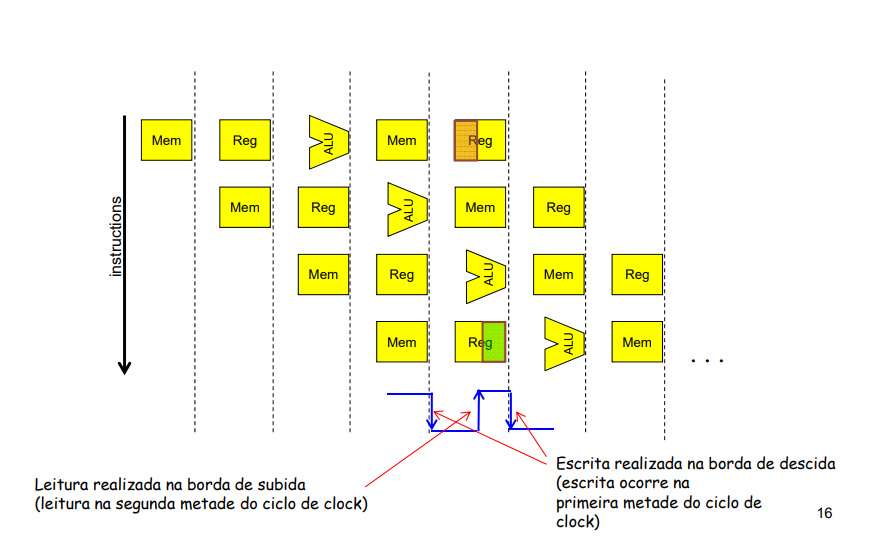
Uso simultâneo de registradores
O caso de conflito causado pelo uso simultâneo de registradores pode ser resolvido de uma forma simples e sem perda de desempenho: basta que o registrador realize a leitura na borda de subida de clock e a escrita na borda de descida. Com esse tipo de implementação evitam-se os conflitos de leitura e escrita simultânea em um mesmo registrador.
Hazards de controle
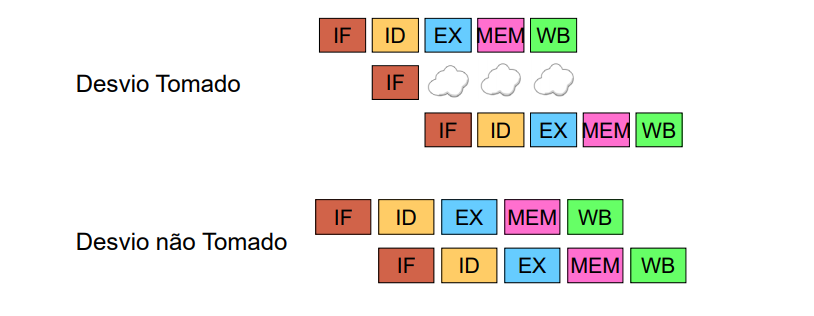
Os hazards de controle estão ligados a instruções do tipo branch e ao controle de fluxo do programa. O que ocorre é que a instrução subsequente ao branch é buscada no próximo ciclo de clock, porém o resultado que determina qual é essa instrução a ser buscada ainda não foi produzido.
Uma solução imediata seria inserir um stall após cada instrução branch, para que seja possível determinar se o salto ocorrerá ou não antes de carregar a próxima instrução. O problema dessa implementação é que há uma perda de desempenho desnecessária quando o desvio não é tomado. Para contornar essa perda de desempenho assume-se então que o desvio nunca será tomado, ou seja, a próxima instrução é sempre carregada. Porém quando o desvio for tomado é introduzida a stall necessária para que a instrução correta seja carregada.
Hazards de dados
Os hazards de dados ocorrem quando uma instrução depende da conclusão de uma instrução prévia que ainda esteja sendo executada.
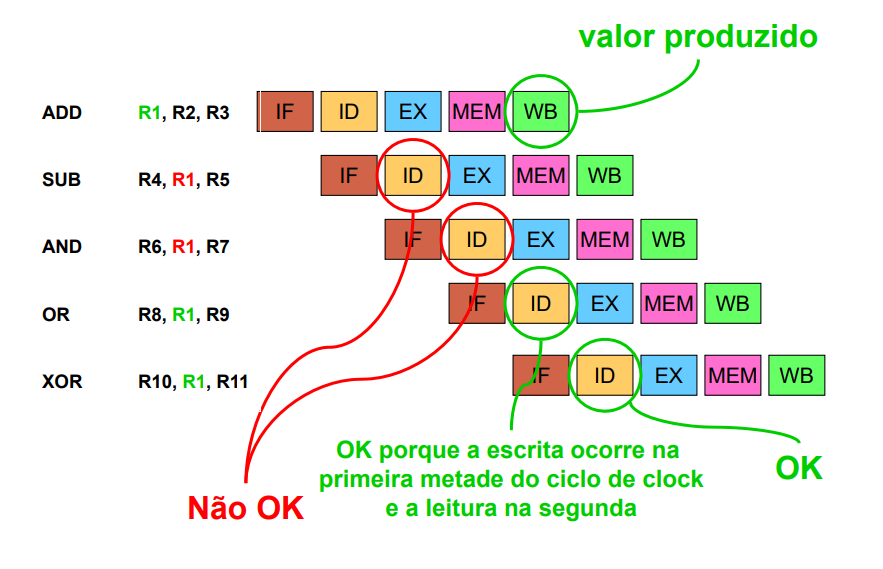
Pode-se usar paradas, porém uma solução mais eficiente é utilizar o encaminhamento (forwarding) dos dados.
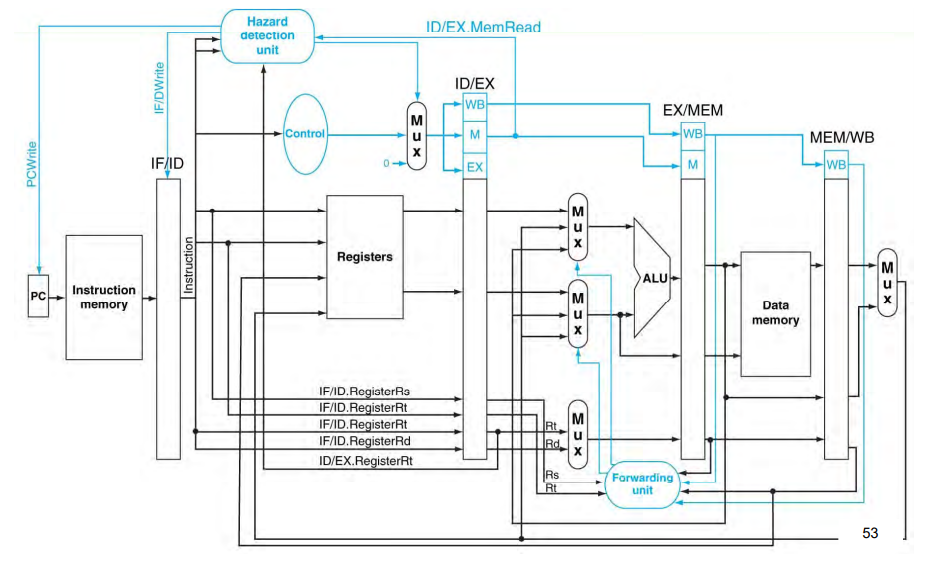
Forwarding
O forwarding (ou bypassing) consiste em implementar uma forma de recuperar a uma informação gerada por uma instrução e encaminhá-la diretamente para a próxima.
Observa-se que em uma instrução de tipo R o resultado da operação já está disponível nos registradores de pipeline antes de ser gravado na memória. A ideia então é implementar um mecanismo que permita que esses registradores sejam acessados diretamente pelas instruções caso necessário, diminuindo assim a necessidade de stalls para aguardar os ciclos de escrita e leitura do dado.
A implementação de forwarding é feita através de um novo circuito lógico para determinar se o valor lido por uma instrução se encontra no banco registradores ou se está sendo processado e se encontra nos registradores de pipeline.
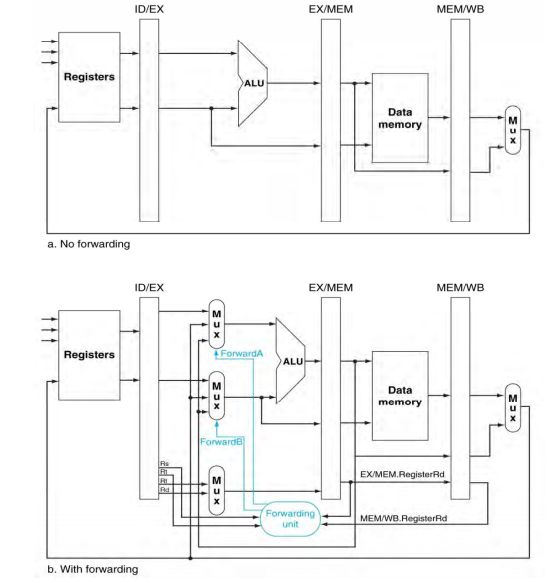
Vale destacar que o forwarding é uma boa solução para muitos casos, porém não resolve todos os conflitos. Há casos em que mesmo com a implementação de forwarding ainda é necessário o uso de stalls para resolver possíveis conflitos, para determinar a necessidade das stalls é necessário o uso de pipeline interlock.
O pipeline interlock é a implementação de um mecanismo que determina se um ou mais stalls devem ser inseridos após a emissão de uma instrução.