A avaliação de algoritmos de Aprendizado supervisionado consiste em testar o modelo obtido através de um algoritmo utilizando exemplos cujo resultado esperado já é conhecido.
O primeiro passo para a avaliação é fazer uma amostragem do conjunto de dados inicial, dividindo o conjunto em um conjunto de treinamento e um conjunto de teste. Dessa forma, é possível testar o modelo utilizando dados que não foram utilizados no treinamento, tornando a avaliação mais confiável. Os principais métodos de amostragem são:
- Resubstituição: o modelo é treinado e testado com o mesmo conjunto de dados
- Holdout: o conjunto de dados original é divido em uma porcentagem fixa de exemplos para treinamento e teste
- Cross-validation: o conjunto de dados com exemplos é dividido aleatoriamente em partições de tamanho , sendo que uma das partições é utilizada para teste, enquanto as outras são utilizadas para treinamento. O treinamento é repetido vezes, cada vez com uma partição de teste diferente. Nesse método o erro é dado pela média dos erros de cada um dos treinamentos
Feita a amostragem dos conjuntos de treinamento e teste, é necessário avaliar o modelo gerado verificando as predições feitas para os dados do conjunto de teste. Uma ferramenta fundamental para a avaliação das predições é a matriz de confusão, que relaciona os resultados esperados com os resultados de fato produzidos pelo modelo quando aplicado ao conjunto de dados de teste.
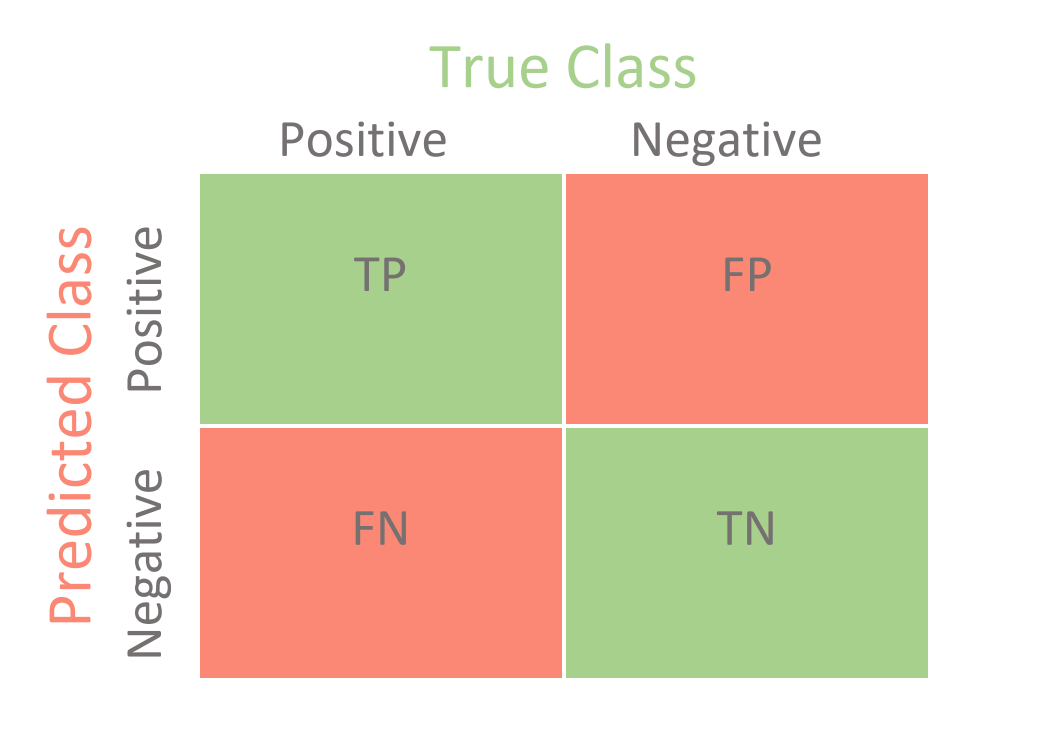
Com base na matriz de confusão, é possível classificar os resultados em tipos:
- True positive (TP): a classe predita é positiva e a classe esperada também.
- False positive (FP) (erro tipo ): a classe predita é positiva mas a classe esperada era negativa.
- True negative (TN): a classe predita é negativa e a classe esperada também.
- False negative (FN) (erro tipo ): a classe predita é negativa mas a classe esperada era positiva.
Vale notar que a matriz de confusão pode ser facilmente estendida para problemas nos quais há muitas classes possíveis.
Com os resultados verificados na matriz de confusão, é possível derivar métricas de avaliação que nos permitem determinar com maior precisão a qualidade dos resultados produzidos pelo modelo.
- A acurácia representa a frequência com a qual o classificador previu corretamente a classe:
- A precisão representa a proporção de acertos do modelo para uma determinada classe:
- A revocação (recall) representa a proporção de exemplos classificados em uma classe com relação ao total de exemplos daquela classe: .
- O F-score combina as medidas de precisão e revocação, obtendo um resultado mais completo que descreve o quão bom é o classificador: .