Índices são estruturas auxiliares que tem por objetivo melhorar a eficiência da busca por registros em um Arquivo. Índices são extensivamente usados em SGBDs.
É possível buscar por registros diretamente no arquivo que contém aquele registro. Entretanto, dada a organização potencialmente complexa dos registros em um arquivo, essa busca pode se tornar ineficiente pela falta de bons métodos de busca a serem aplicados diretamente nos arquivos.
Geralmente um índice é implementado como um arquivo separado composto por registros de tamanho fixo, que por sua vez são compostos por campos de tamanho fixo. Essa escolha de organização dos arquivos de índices torna seu acesso muito simples, e como geralmente não há grande variabilidade nos dados armazenados, o desperdício de espaço é justificável em virtude da melhora na eficiência da busca.
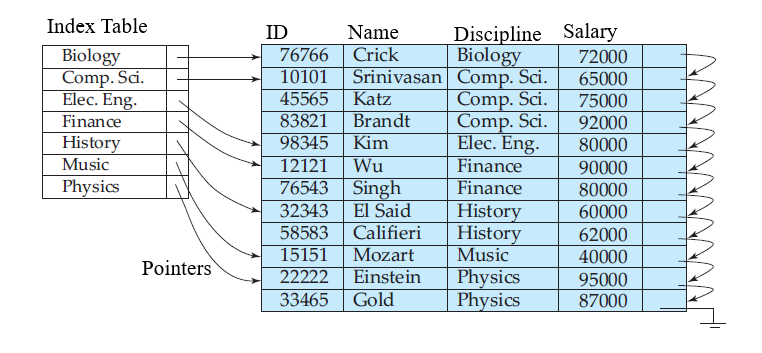
Cada registro de um índice armazena dois dados:
- Uma chave de busca que permite identificar o registro buscado no arquivo principal. Essa chave pode ser tanto um campo quanto uma combinação de campos do arquivo principal.
- Um campo de referência que indica a posição do registro no arquivo através do RRN ou do byte offset.
Além disso, os registros dos índices geralmente são ordenados de acordo com a chave de busca. Dessa forma, é possível aplicar algoritmos de busca mais eficientes, como a busca binária para encontrar rapidamente a posição do campo no arquivo principal.
Tipos de índices
Em geral, existem duas classificações para índices de acordo com a ordem de seus registros:
- Em um índice agrupado a ordem dos registros é a mesma ou muito próxima à ordem dos registros no arquivo principal.
- Em um índice não agrupado a ordem dos registros não coincide com a ordem dos registos no arquivo principal.
Além disso, os arquivos de índices podem ser classificados de acordo com a quantidade de entradas de índice em relação à quantidade de registros no arquivo principal:
- Um índice denso armazena um registro para cada registro no arquivo principal. Dessa forma, é possível acessar diretamente o registro no arquivo principal. Note que esse tipo de índice ocupa um espaço diretamente proporcional ao tamanho do arquivo principal.
- Um índice esparso armazena um registro para cada página no arquivo principal. Assim, é possível acessar apenas a página do registro, sendo necessário finalizar a busca pela chave desejada no próprio arquivo. Apesar, de oferecer uma busca menos eficiente do que um índice denso, um índice esparso ocupa menos espaço. Vale notar também que esse tipo de índice necessariamente deve ser agrupado, pois a ordem dos registros é fundamental para localizar sua página.
Manutenção e organização
Com a criação de um índice, é introduzida uma dificuldade: sua manutenção. Para que o índice continue sendo eficiente, as mudanças no arquivo principal devem ser refletidas também no arquivo de índice. Isso inclui as operações de remoção, inserção, atualização entre outras.
Quando o arquivo de índice pode ser carregado diretamente na memória, pode-se utilizar a estratégia de organização linear, na qual o índice é carregado na memória principal como um array e são empregados algoritmos de busca para encontrar os registros desejados. Entretanto, nem sempre é possível carregar o arquivo de índice inteiro na memória. Nesses casos, é mais eficiente utilizar outras formas de organização, como hashing ou árvores B, com o objetivo de minimizar os acessos a disco e, consequentemente, tornar a busca mais eficiente.
Índices secundários
Um índice secundário é definido com base em uma chave secundária, que identifica um ou mais registros no arquivo principal. Podem ser definidos diversos índices secundários para um arquivo, permitindo que a busca seja otimizada para diversas chaves secundárias.
Em geral, existem dois tipos de índices secundários:
- Índices fracamente ligados relacionam a chave secundária à chave primária do registro no índice principal. Esse tipo de índice reduz a complexidade de manutenção, pois algumas (mas nem todas) mudanças no arquivo principal podem ser refletidas apenas no índice principal, sem a necessidade de alterar os índices secundários.
- Índices fortemente ligados relacionam a chave secundária diretamente ao registro no arquivo principal. A busca nesse tipo de índice é mais eficiente do que a com índices fracamente ligados, pois é possível acessar o registro diretamente, sem fazer uma busca intermediária no índice principal. Entretanto, a complexidade de manutenção desse tipo de índice é maior se comparada à de índices fracamente ligados.
Note que nos índices secundários pode haver repetição das chaves secundárias, pois eles não são necessariamente únicas. Essa repetição pode ocasionar ineficiência de armazenamento e aumentar o custo de manutenção desses índices. Tendo isso em vista, são propostos duas soluções:
- Associar um vetor de tamanho fixo a cada chave secundária. Dessa forma, ao invés de múltiplos registros com a mesma chave secundária, o arquivo armazena apenas um registro para cada chave secundária, associando esta à um vetor de chaves primárias ou a posição dos registros no arquivo principal. Nessa estratégia é desnecessário reordenar o índice secundário a cada inserção de chave secundária repetida. Entretanto, pela natureza fixa dos vetores, a fragmentação interna no índice pode se tornar um problema.
- Associar uma lista encadeada das chaves primárias (ou posições dos registros no arquivo principal) a cada chave secundária. A implementação dessa lista em arquivos pode ser feita da seguinte maneira: cada registro no índice secundário armazena a chave secundária e o RRN do primeiro registro associado à chave secundária na lista encadeada; cada registro da lista invertida armazena a chave primária, o byte offset do registro no arquivo principal, e o RRN do próximo elemento da lista encadeada. Essa estratégia torna a organização do índice secundário mais simples e eficiente, porém não garante que as chaves primárias associadas a uma mesma chave secundária estejam adjacentes no disco, potencialmente prejudicando o desempenho da busca.